Использование в качестве инструмента для моделирования программного обеспечения KXEN предлагает усовершенствовать аналитический процесс, устранив трудности, часто возникающие в процессе поиска закономерностей, среди которых: трудоемкость подготовки данных; сложность выбора переменных, включенных в модель; требования к квалификации аналитиков; сложность интерпретации полученных результатов; сложность построения моделей. Эти и другие проблемы были нами рассмотрены на протяжении курса лекций.
Особенность KXEN заключается в том, что заложенный в него математический аппарат (на основе Теории минимизации структурного риска Владимира Вапника) позволяет практически полностью автоматизировать процесс построения моделей и на порядок увеличить скорость проводимого анализа. Отличия традиционного процесса Data Mining и подхода KXEN приведены на рис. 27.1.
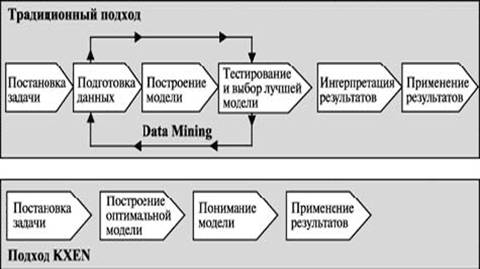
Таким образом, построение модели в KXEN из исследовательского проекта превращается в функцию предсказательного анализа в режиме on-line в формате "вопрос-ответ". Причем ответы даются в тех же терминах, в которых был сформулирован вопрос, и задача пользователя сводится к тому, чтобы задавать нужные вопросы и указывать данные для анализа.
Среди преимуществ KXEN можно назвать:
• Удобная и безопасная работа с данными: данные никуда не перегружаются, KXEN обрабатывает их строка за строкой (текстовые файлы или интеграция с DB2, Oracle и MS SQL Server, в т.ч. через ODBC);
• Наглядность результатов моделирования, легкость для понимания: графическое отображение моделей + score-карты;
• Широкие возможности применения моделей: автоматическая генерация кода моделей на языках С++, XML, PMML, HTML, AWK, SQL, JAVA, VB, SAS, при этом модель сможет работать автономно.
